📋 목차
Text-to-image diffusion model은 텍스트로 이미지를 생성하는 데는 강력하지만, 기존 이미지의 구조를 유지하면서 의미와 외형을 바꾸는 것은 여전히 어렵다. SDEdit 같은 방법은 구조 보존과 text fidelity 사이에 본질적인 trade-off가 있고, Prompt-to-Prompt는 cross-attention 조작 기반이라 fine-grained structure 제어에 한계가 있다.
Semantic translation
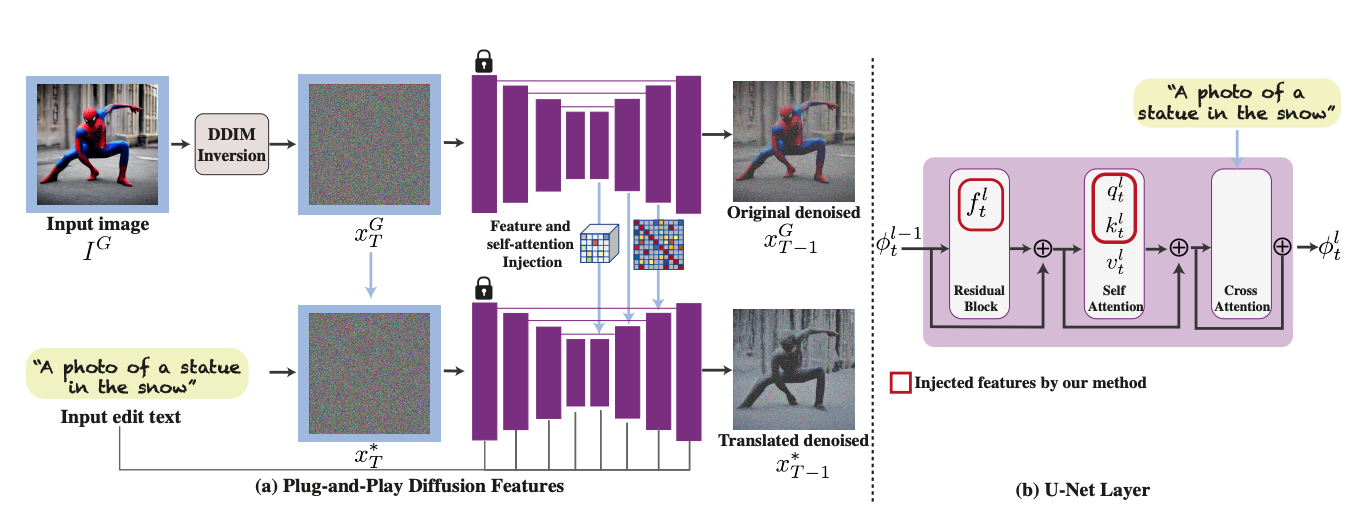
PnP Diffusion은 이 한계를 태클한다. Pre-trained Stable Diffusion 내부의 spatial feature와 self-attention을 generation 과정에 직접 주입해서, 추가 training 없이 guidance image의 구조를 유지하면서 target text에 맞는 semantic translation을 수행한다. Training-free라는 점, 그리고 real image까지 다룬다는 점이 인상적이다.

핵심 용어 정리
Plug-and-Play Diffusion Features (PnP Diffusion)
Pre-trained text-to-image diffusion model 내부의 spatial features와 self-attention을 generation 과정에 직접 주입해서, 별도 training 없이 text-guided image-to-image translation을 수행하는 framework다.
DDIM Inversion
Real guidance image를 diffusion latent trajectory로 되돌려서, 해당 이미지에 대응하는 초기 noise $x_T^G$를 얻는 과정이다. 이 논문은 real image를 다루기 위해 이 inversion을 핵심 전처리로 사용한다.
Spatial Features
U-Net decoder 내부의 intermediate feature map이다. 저자들은 이 feature가 object part 수준의 localized semantic information을 담고 있으며, appearance보다 structure와 semantic layout을 더 잘 반영한다고 분석한다. 특히 중간 decoder layer가 중요하다.
Self-Attention / Self-Affinity
Spatial feature들 사이의 affinity를 나타내는 attention matrix $A_t^l$이다. 저자들은 이것이 fine-grained shape, part relationship, layout consistency를 유지하는 데 중요하다고 보고, feature injection과 함께 attention injection을 수행한다.
Negative Prompting
Unconditional branch 대신 negative prompt를 사용해, 생성 결과를 원본 guidance appearance로부터 멀어지게 만드는 방식이다. 특히 textureless하거나 primitive한 guidance image에서 더 유의미하다.
문제 정의
이 논문의 핵심 문제는, text-to-image diffusion model은 강력하지만 사용자가 원하는 구조적 제어가 어렵다는 점이다. 텍스트만으로는 “무엇을 그릴지”는 비교적 잘 제어할 수 있지만, 입력 이미지의 semantic layout, object pose, fine-grained structure를 유지한 채 다른 의미와 appearance로 바꾸는 것은 쉽지 않다.
기존 접근의 한계는 세 가지로 정리할 수 있다.
-
Additional control signal 방식의 한계 — segmentation mask 기반 모델은 대규모 paired training data와 큰 compute가 필요하고, test-time에도 특정 control format에 묶인다. 저자들은 sketch, drawing, real photo 등 다양한 guidance signal을 하나의 unified framework로 처리하고 싶어 한다.
-
Cross-attention 조작의 한계 — Prompt-to-Prompt(P2P) 같은 방식은 object-level region 대응은 가능하지만, text에 명시되지 않은 localized spatial detail(object part, 미세한 shape)은 충분히 보존하지 못한다.
-
SDEdit의 구조적 trade-off — noise를 적게 주면 원본 구조는 남지만 edit가 약하고, noise를 많이 주면 text fidelity는 올라가지만 구조가 무너진다.
문제 정의는 명확하다.
“Pre-trained, fixed Stable Diffusion 내부 representation만 활용해서, 추가 training 없이 guidance image의 구조를 강하게 유지하면서도 target prompt에 맞는 semantic translation을 구현할 수 있는가?”
제안 방법론
핵심 아이디어
저자들의 가장 중요한 관찰은 두 가지다.
- Intermediate decoder features는 localized semantic information을 담는다
- Self-attention map은 spatial feature들 간 affinity를 통해 fine layout과 shape detail을 유지한다
이를 바탕으로, guidance image $I^G$를 DDIM inversion으로 latent noise $x_T^G$로 바꾼 뒤, 그 latent를 denoising하면서 매 step에서 decoder feature $f_t^l$와 self-attention $A_t^l$를 추출한다. Translated image를 생성할 때도 같은 초기 noise $x_T^* = x_T^G$를 사용하고, target prompt $P$ 조건 하에서 denoising을 진행하면서 guidance에서 추출한 feature/attention을 내부에 주입한다.
PCA visualization
PCA visualization으로 diffusion feature를 분석한다. Decoder intermediate layer 4가 appearance variation을 넘어서 legs, torso, head 같은 semantic parts를 일관되게 encode하는 것으로 나타난다. 반면 더 shallow layer는 foreground/background 수준이고, deeper layer는 점차 high-frequency, appearance-heavy 정보가 강해진다.

Deeper layer feature까지 강하게 주입하면 structure는 잘 맞지만 appearance leakage가 생길 수 있다.
왜 self-attention까지 같이 주입하나?
Feature만 넣으면 semantic association은 생기지만 fine structure가 충분히 고정되지 않는다. 반대로 attention만 넣으면 structure affinity는 유지되지만, 원본 content와 target content 사이 semantic correspondence가 부족해진다.

저자들의 결론은 이 둘의 조합이 핵심이라는 것이다.
- Feature injection → semantic association 확보
- Self-attention injection → 구조적 affinity와 fine layout 유지
논문에서 feature only, feature + attention, attention only를 비교하며, 최종 구성이 가장 균형이 좋다고 보여준다.
Injection Scheduling
두 개의 threshold를 둔다.
- $\tau_f$: feature injection을 유지할 sampling step
- $\tau_A$: self-attention injection을 유지할 sampling step
기본 설정은 50-step DDIM sampling 기준 $\tau_A = 25$, $\tau_f = 40$이다. Primitive guidance image에서는 $\tau_A = \tau_f = 25$가 더 낫다고 보고한다.
Negative Prompting
Classifier-free guidance에서 unconditional branch 대신 negative prompt를 섞어, 결과가 원본 guidance appearance에서 더 멀어지게 만든다. 다만 이 효과는 natural image에서는 minor하고, textureless primitive image에서 더 의미 있다.
핵심 결과
실험 세팅
논문은 기존 benchmark가 없어서 두 가지를 직접 구축한다.
- Wild-TI2I: 총 148개 text-image pair, 53%는 웹에서 수집한 real guidance image
- ImageNet-R-TI2I: ImageNet-R 기반, 10 classes × 3 images × 5 prompts = 총 150개 pair
평가 metric은 두 축이다.
- CLIP cosine similarity: target text compliance (높을수록 좋음)
- DINO-ViT self-similarity distance: structure preservation (낮을수록 좋음)
Baseline 비교
핵심은 baseline들이 구조 보존과 text fidelity를 동시에 만족시키지 못하는 반면, PnP Diffusion은 그 균형이 가장 좋다는 점이다. SDEdit은 noise level에 따라 한쪽만 잘하고, P2P는 text는 잘 맞아도 structure deviation이 커지고, DiffuseIT는 shape fidelity는 높지만 appearance 변화가 약하다. PnP Diffusion은 낮은 structure distance와 높은 CLIP similarity 사이에서 가장 좋은 Pareto balance를 보인다.
Ablation
Feature나 self-attention을 제거하면 structure 보존 지표가 크게 악화된다.
Wild-TI2I Real:
| 구성 | Self-Sim ↓ | CLIP ↑ | LPIPS |
|---|---|---|---|
| Full method | 0.058 | 0.282 | 0.521 |
| w/o feature | 0.090 | 0.288 | 0.584 |
| w/o self-attn | 0.097 | 0.286 | 0.597 |
ImageNet-R-TI2I:
| 구성 | Self-Sim ↓ | CLIP ↑ | LPIPS |
|---|---|---|---|
| Full method | 0.051 | 0.275 | 0.462 |
| w/o feature | 0.076 | 0.281 | 0.534 |
| w/o self-attn | 0.089 | 0.278 | 0.564 |
CLIP score는 비슷해 보여도 structure distance가 크게 나빠진다. Feature와 attention이 모두 structure preservation에 critical하다는 주장과 정확히 맞는 결과다.
결론 및 시사점
이 논문은 Stable Diffusion 내부의 diffusion feature가 단순 noise denoising 중간값이 아니라, semantic layout과 fine structure를 encode하는 유의미한 representation이라는 점을 실험적으로 보여준다. 그리고 이 representation을 이용해, decoder intermediate feature와 self-attention을 plug-and-play 방식으로 주입하면, 추가 학습 없이도 고품질 text-driven image-to-image translation이 가능하다는 것을 제시한다.
연구 관점에서는, diffusion model의 내부 feature space를 controllable하고 semantically organized된 internal space로 다루는 연구 흐름을 강하게 연 논문이다. 산업 관점에서는, 별도 task-specific training 없이도 reference image 기반 controllable editing, style transfer, semantic object replacement에 바로 응용 가능하다는 점이 크다.
한계는 guidance와 target 사이 semantic association이 거의 없는 경우(arbitrary color segmentation mask 등)에는 잘 동작하지 않는다고 인정한다. 또한 DDIM inversion 품질에 일부 의존한다는 점도 실무에서 고려해야 할 부분이다.