📋 목차
들어가며
Local feature matching은 SfM, visual localization, SLAM 등 3D vision의 거의 모든 downstream task에서 기초가 되는 문제다. 전통적으로는 feature extraction → descriptor → matching의 3단계 pipeline을 따르는데, 이 구조는 detector가 안정적인 keypoint를 잘 찾아야만 나머지가 의미가 있다. 문제는 indoor scene이나 low-texture 영역에서는 detector가 제대로 작동하지 않는 경우가 많다는 것이다.
LoFTR는 이 문제를 정면으로 태클한다. Keypoint를 먼저 뽑지 않고, 두 image의 dense feature를 Transformer로 jointly transform한 뒤 직접 matching하는 detector-free 구조를 제안한다. 특히 self-attention과 cross-attention을 통해 global context를 feature에 녹여내서, texture가 부족한 영역에서도 robust한 correspondence를 만든다는 점이 인상적이다.
핵심 용어 정리
LoFTR (Local Feature TRansformer)
기존 detector-based pipeline처럼 keypoint를 먼저 뽑지 않고, image pair 전체에서 detector-free하게 correspondence를 찾는 local feature matching framework다. Coarse-to-fine 구조와 Transformer 기반 global context modeling이 핵심이다.
Detector-Free Matching
Interest point detector에 의존하지 않고, dense 또는 semi-dense feature representation에서 직접 correspondence를 추정하는 방식이다. LoFTR는 이 설계를 통해 low-texture region이나 repetitive pattern 영역에서도 match를 생성할 수 있다.
Self-Attention / Cross-Attention
Self-Attention은 각 image 내부에서 context를 집계하고, Cross-Attention은 두 image 사이의 feature interaction을 학습한다. LoFTR는 이 둘을 반복적으로 interleave하여 feature를 context-dependent이면서 match-aware하게 변환한다.
Linear Transformer
Vanilla attention의 $O(N^2)$ complexity를 줄이기 위해 도입된 efficient attention variant다. LoFTR는 coarse feature map 전체에 attention을 적용해야 하므로, 계산량을 manageable하게 만들기 위해 linear attention을 사용한다.
Coarse-to-Fine Refinement
먼저 1/8 resolution의 coarse feature에서 match를 찾고, 이후 fine feature patch에서 local correlation과 expectation을 통해 sub-pixel 수준으로 refinement하는 구조다. 이 단계 덕분에 geometry-sensitive task에서 정확도가 크게 올라간다.
문제 정의
기존의 detector-based 방법은 repeatable interest point를 먼저 잘 찾아야만 이후 단계가 의미가 있다. 문제는 실제 장면에서는 poor texture, repetitive patterns, viewpoint change, illumination variation, motion blur 때문에 detector가 안정적인 점을 못 찾는 경우가 많다는 점이다. 논문은 특히 indoor scene에서 이 문제가 심각하다고 강조한다.
기존 detector-free dense matching 계열도 있었지만, 여전히 한계가 있었다. NCNet, Sparse-NCNet, DRC-Net 같은 방법은 dense correspondence를 다루지만, 주로 CNN 혹은 4D cost volume 기반이라 local neighborhood consensus에는 강해도 충분한 global receptive field를 주지 못한다. 즉, “이 texture-less pixel이 어디와 대응되는지”를 판별할 때 주변 작은 patch만 봐서는 부족하고, 더 넓은 scene context가 필요하다는 것이다.
그래서 저자들은 문제를 이렇게 재정의한다.
“Repeatable keypoint detection 자체에 의존하지 말고, 두 image의 dense local feature를 global context까지 포함해 jointly transform한 뒤 직접 matching하면 어떨까?”
이게 바로 LoFTR의 출발점이다. Transformer의 global receptive field를 local matching에 들여와서, detector가 약한 영역에서도 correspondence를 만들겠다는 발상이다.
제안 방법론
전체 pipeline은 4단계로 정리된다.
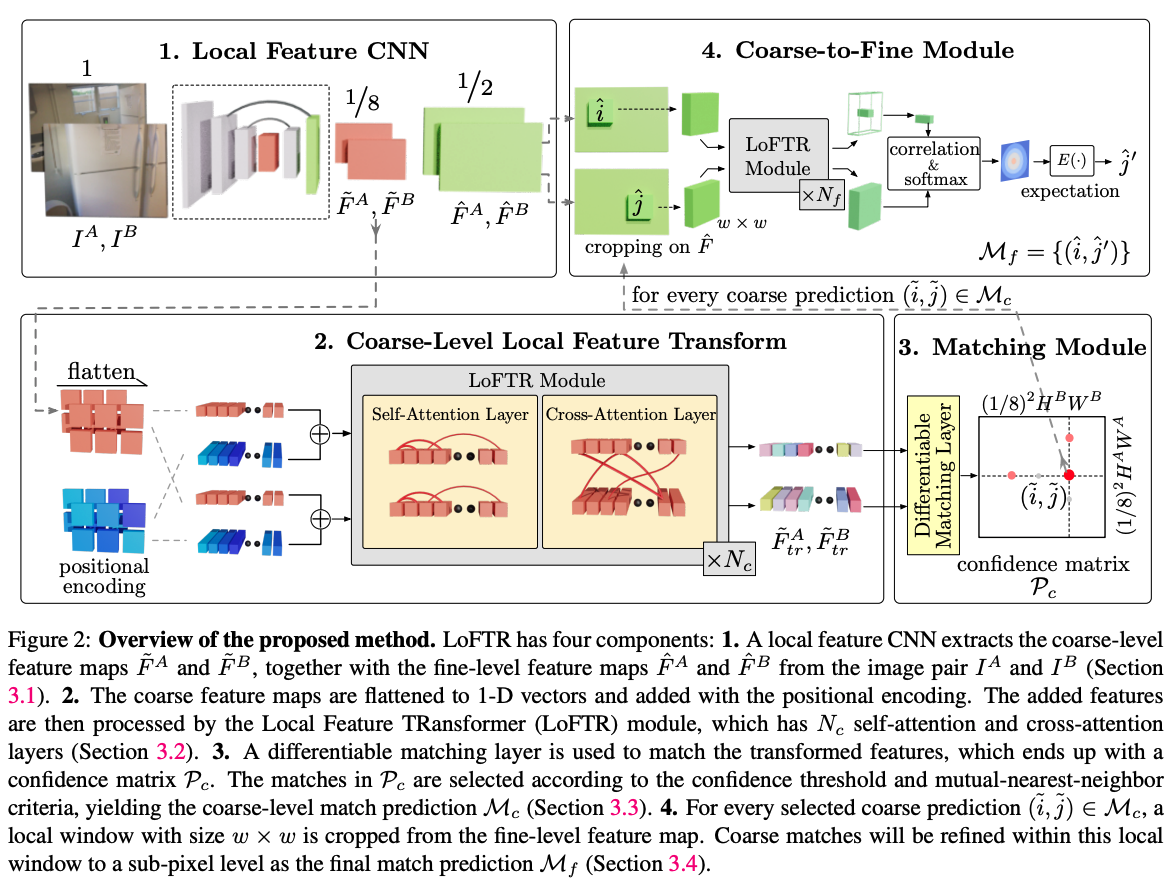
Stage 1: Local Feature CNN
먼저 backbone CNN + FPN으로 multi-level feature를 추출한다.
- Coarse feature: 원본의 1/8 resolution
- Fine feature: 원본의 1/2 resolution
처음부터 full-resolution dense matching을 하지 않고, 계산량을 줄이기 위해 coarse representation에서 먼저 broad match를 찾는 구조다.
Stage 2: Local Feature Transformer (LoFTR Module)
Coarse feature map을 flatten한 뒤 positional encoding을 더하고, 그 위에 $N_c$번의 self-attention + cross-attention block을 적용한다. 이 단계의 목적은 단순 descriptor extraction이 아니라, feature를 position-dependent하고 context-dependent하게 바꾸는 것이다.
CNN의 local receptive field와 Transformer의 global receptive field 차이가 여기서 드러난다.
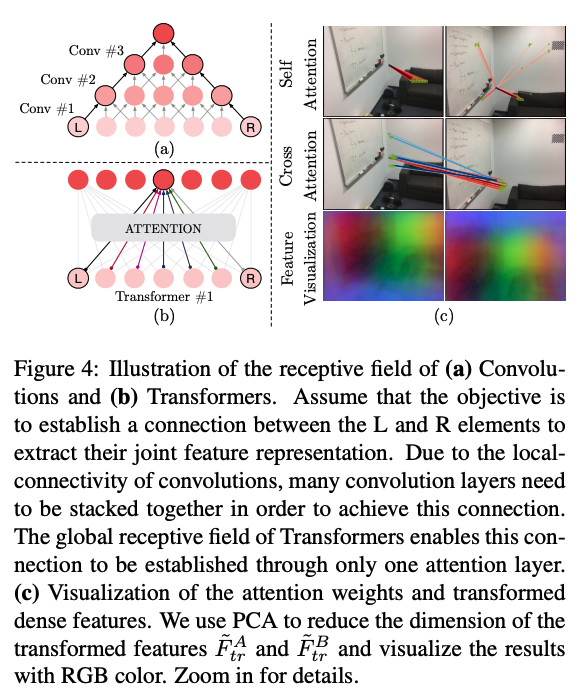
Low-texture wall 같은 곳도 edge와의 상대적 위치 정보를 통해 구분 가능하다는 것이 핵심이다.
Coarse map 전체에 attention을 걸어야 하므로, vanilla attention($O(N^2)$) 대신 Linear Transformer를 사용해 $O(N)$으로 complexity를 줄인다.
Stage 3: Coarse-Level Matching
Transformed coarse feature들 사이의 similarity score matrix $S$를 만든 뒤, differentiable matching layer로 confidence matrix $P_c$를 생성한다. Matching layer는 두 가지 variant가 있다:
- Optimal Transport (OT): Sinkhorn 기반
- Dual-Softmax (DS): 양쪽 softmax의 곱
이후 confidence threshold와 Mutual Nearest Neighbor(MNN) 조건으로 coarse matches $M_c$를 선택한다. 즉, coarse stage는 후보 correspondence를 안정적으로 좁히는 단계다.
Stage 4: Coarse-to-Fine Refinement
선택된 coarse match마다 fine feature map에서 local window를 crop하고, 더 작은 LoFTR module을 patch 단위에 적용한다. 한쪽 center feature와 다른 쪽 patch 전체를 correlation하여 heatmap을 만들고, expectation으로 최종 sub-pixel position을 얻는다. 이로써 최종 fine matches $M_f$를 생성한다.
Training
Loss는 coarse loss $L_c$와 fine loss $L_f$의 합이다.
- Coarse stage: confidence matrix에 대한 negative log-likelihood
- Fine stage: uncertainty-weighted $L_2$ loss
Ground-truth coarse match는 camera pose와 depth map을 이용한 reprojection 기반으로 구성한다. 즉, pure image similarity supervision이 아니라 geometry-aware supervision을 강하게 활용한다.
핵심 결과
HPatches Homography Estimation
| 모델 | AUC@3px | AUC@5px | AUC@10px |
|---|---|---|---|
| DRC-Net | 50.6 | 56.2 | 68.3 |
| SP + SuperGlue | 53.9 | 68.3 | 81.7 |
| LoFTR-DS | 65.9 | 75.6 | 84.6 |
Stricter threshold일수록 격차가 커진다는 점이 중요하다. 단순히 match 수만 많은 게 아니라 geometric precision도 높다는 뜻이다.
ScanNet Indoor Relative Pose
| 모델 | AUC@5° | AUC@10° | AUC@20° |
|---|---|---|---|
| DRC-Net† | 7.69 | 17.93 | 30.49 |
| SP + SuperGlue | 16.16 | 33.81 | 51.84 |
| LoFTR-OT | 21.51 | 40.39 | 57.96 |
| LoFTR-DS | 22.06 | 40.80 | 57.62 |
Indoor low-texture scene에서 detector-free + global context가 특히 강력하다는 메시지다.
MegaDepth Outdoor Relative Pose
| 모델 | AUC@5° | AUC@10° | AUC@20° |
|---|---|---|---|
| DRC-Net | 27.01 | 42.96 | 58.31 |
| SP + SuperGlue | 42.18 | 61.16 | 75.96 |
| LoFTR-DS | 52.80 | 69.19 | 81.18 |
논문 본문도 SuperGlue 대비 AUC@10°에서 13%, DRC-Net 대비 61% 개선이라고 직접 강조한다.
Visual Localization
Aachen Day-Night benchmark에서 night query local feature evaluation에서 72.8 / 88.5 / 99.0을 기록했고, InLoc benchmark에서는:
| Scene | (0.25m, 10°) | (0.5m, 10°) | (1.0m, 10°) |
|---|---|---|---|
| DUC1 | 47.5 | 72.2 | 84.8 |
| DUC2 | 54.2 | 74.8 | 85.5 |
특히 InLoc처럼 texture-less area, symmetry, repetitive structure가 많은 indoor localization에서 강점을 보인다.
Runtime
640×480 image pair 기준:
- Dual-Softmax version: 116 ms
- Optimal Transport version: 130 ms
Ablation 요약
- LoFTR module을 convolution으로 대체하면 성능이 크게 떨어짐
- Positional encoding을 layer마다 넣는 DETR-style design도 오히려 성능이 하락
- 즉, 이 논문의 성능은 단순히 Transformer를 넣어서 나온 게 아니라, coarse resolution + one-time positional encoding + coarse-to-fine refinement의 조합이 핵심이다
결론 및 시사점
이 논문의 핵심 기여는 local matching 문제를 더 이상 “좋은 keypoint를 먼저 detect하는 문제”로 보지 않고, 두 image의 dense feature를 global context 하에서 jointly transform한 뒤 coarse-to-fine으로 correspondence를 찾는 문제로 재정의했다는 점이다. LoFTR는 self-attention과 cross-attention을 통해 feature를 context- and position-dependent하게 만들고, detector가 잘 동작하지 않는 low-texture / repetitive region에서도 robust한 semi-dense matching을 만든다. 실험적으로도 HPatches, ScanNet, MegaDepth, Aachen, InLoc 전반에서 당시 SOTA를 달성했다.
이 논문은 이후 detector-free matcher 계열의 기준점이 되었고, Efficient LoFTR, AspanFormer, TopicFM 같은 후속 연구들이 사실상 이 구조를 기준으로 efficiency나 accuracy를 개선해 나간다. 특히 3D reconstruction 관점에서는, LoFTR가 weak texture region에서도 더 많은 valid correspondence를 제공하기 때문에 SfM initialization, pose estimation, visual localization, low-feature overlap scene 처리에 큰 영향을 준다.
다만 Coarse feature map 전체에 Transformer를 올리는 구조라 runtime과 memory cost가 무겁고, 이 점이 바로 후속 Efficient LoFTR가 파고든 병목이다. 원조 LoFTR는 “왜 detector-free Transformer matching이 통하는가”를 증명한 논문이고, Efficient LoFTR는 “그걸 어떻게 practical하게 만들 것인가”에 대한 연구다.